파이썬의 메모리 관리
25 Jul 2022언어에서의 메모리 관리
프로그래밍 언어는 연산을 수행하기 위해 프로그램의 객체를 사용한다. 객체에는 문자열, 정수 또는 부울과 같은 간단한 변수가 포함된다. 또한 목록, 해시 또는 클래스와 같은 더 복잡한 데이터 구조를 포함한다.
프로그램 객체의 값은 빠른 액세스를 위해 메모리에 저장된다. 많은 프로그래밍 언어에서 프로그램 코드의 변수는 단순히 메모리에 있는 객체의 주소에 대한 포인터이다. 프로그램에서 변수가 사용될 때 프로세스는 메모리에서 값을 읽고 작동한다.
초기 프로그래밍 언어에서 대부분의 개발자는 프로그램의 모든 메모리 관리를 담당했다. 즉, 리스트나 객체를 만들기 전에 먼저 변수에 메모리를 할당해야 했다. 변수를 사용한 후에는 다른 사용자에게 해당 메모리를 “사용 가능한” 상태로 만들기 위해 직접 할당 해제했다.
이로 인해 두 가지 문제가 발생하였다.
메모리 반환을 잊는 경우. 사용 후 메모리를 확보하지 않으면 메모리 누수가 발생할 가능성이 있다. 이로 인해 시간이 지남에 따라 프로그램이 너무 많은 메모리를 사용하게 될 수 있었다. 장시간 실행되는 애플리케이션의 경우 심각한 문제가 발생하기도 했다.
반대로, 메모리를 너무 빨리 반환하는경우 즉, 메모리가 아직 사용 중일 때 메모리를 분리하는 것이다. 이로 인해 프로그램이 존재하지 않는 메모리의 값에 액세스하려고 할 경우 프로그램이 중단되거나 데이터가 손상될 수 있다. 해방된 메모리를 가리키는 변수를 dangling 포인터라고 한다.
자동 메모리 관리를 통해 프로그래머는 더 이상 메모리를 직접 관리할 필요가 없어졌다. 오히려 런타임에서 이를 처리했다.
자동 메모리 관리에는 몇 가지 다른 방법이 있다. 레퍼런스 카운팅이 그 예이다. 레퍼런스 카운트를 사용하면 런타임은 객체에 대한 모든 레퍼런스를 추적한다. 객체에 대한 참조가 0이면 프로그램 코드에 의해 사용할 수 없으며 삭제할 수 있다.
프로그래머들에게 자동 메모리 관리는 많은 이점을 더한다. 낮은 수준의 메모리 세부 사항을 생각하지 않고 프로그램을 개발하는 것이 더 빠르다. 게다가, 그것은 값비싼 메모리 누수나 위험한 dangling 포인터를 피할 수 있다.
그러나 자동 메모리 관리에는 비용이 든다. 프로그램이 모든 참조를 추적하려면 추가 메모리와 연산을 사용해야 한다. 게다가, 자동 메모리 관리를 갖춘 많은 프로그래밍 언어들은 가비지 컬렉터를 위해 “스톱 더 월드” 프로세스를 사용한다.
컴퓨터 처리의 발전과 더 큰 양의 RAM으로 인해, 자동 메모리 관리의 이점은 대개 단점을 능가한다. 따라서 대부분의 현대 프로그래밍 언어들은 자동 메모리 관리를 사용한다.
파이썬의 메모리 관리
파이썬의 모든 것은 객체이다. 일부 개체는 목록, 튜플, 딕트, 클래스 등과 같은 다른 개체를 포함할 수 있다. 동적 파이썬의 특성 때문에 이러한 접근 방식은 작은 메모리 할당이 많이 필요하다. 메모리 작업의 속도를 높이고 단편화를 줄이기 위해 파이썬은 범용 할당기 위에 PyMalloc라는 특수 관리자를 사용한다.
우리는 전체 시스템을 계층적 집합으로 묘사할 수 있다.

새 이름을 할당하거나 dict 또는 tuple 같은 컨테이너에 배치하면 레퍼런스 카운트가 값을 증가시킨다. 참조를 객체에 재할당하면 레퍼런스 카운트는 다음 경우에 해당 값이 감소한다. 또한 객체의 참조가 범위를 벗어나거나 객체가 삭제되면 해당 값이 줄어든다.
파이썬은 힙 역역에 의해 관리되는 동적 메모리 할당을 사용한다. 메모리 힙은 프로그램에서 사용될 객체 및 기타 데이터 구조를 보유한다. 파이썬 메모리 매니저는 API 기능을 통해 힙 메모리 공간의 할당 또는 할당 해체를 관리한다
가비지 컬렉터
이 글에서 파이썬의 가비지 컬렉터는 ‘레퍼런스 카운팅’과 ‘세대별 가비지 컬렉션’으로 구별한다.
레퍼런스 카운팅
파이썬에서 모든 객체와 데이터 구조는 개인 힙에 저장되며 내부적으로 파이썬 메모리 매니저에 의해 관리된다. 메모리 관리자의 목표는 메모리 할당을 위해 개인 힙에 충분한 공간이 있는지 확인한다.
파이썬의 변수는 메모리에 있는 객체에 대한 참조일 뿐이다. 정수 객체는 메모리에 저장되며, 변수는 해당 객체의 메모리에 대한 참조이다. 즉 변수는 값을 포함하지 않지만 메모리 주소에 대한 참조를 포함한다. (위와 같은 이유로 파이썬의 변수variable를 이름name이라 칭하지만 이 글에서는 두 표현을 혼용한다)
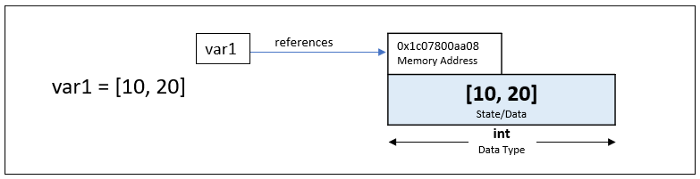
위의 예에서는 메모리주소를 참조하는 변수가 하나만 있다. 그래서 이 객체의 레퍼런스 카운트는 1이다. 이러한 객체의 레퍼런스 카운트는 시스템 모듈의 sys.getrefcount(var1)를 실행하여 알 수 있다.
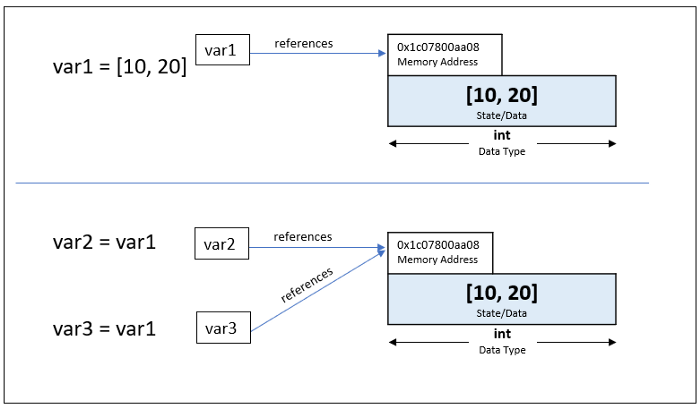
위와 같이 변수를 할당할 경우, 세 개의 변수가 같은 메모리를 참조하여 레퍼런스 z는 3이 된다.
만약 레퍼런스 카운트 변수를 여러 쓰레드가 동시에 값을 늘리거나 줄이는 경쟁 조건이 발생할 경우를 대비하여 파이썬은 GIL(Global Interpreter Lock)을 사용한다. 파이썬은 인터프리터 자체에 대한 단일 잠금으로 바이트 코드를 실행하려면 GIL을 획득해야한다는 규칙을 추가했다. 대신에 모든 파이썬 프로그램을 단일 스레드로 만들었다.
가비지 컬렉션의 순환 참조 감지
파이썬은 레퍼런스 카운팅 외에도 보조적으로 세대별 가비지 컬렉션이라는 방법을 사용한다. 왜 가비지 컬렉션이 필요할까?
객체가 순환 참조하는 경우를 생각하면
객체의 참조 횟수는 1이지만 객체에 더 이상 접근할 수 없으며, 레퍼런스 카운팅 방식으로는 메모리에서 해체되지 않는 상황이 생긴다.
이러한 유형의 문제를 circular reference(순환 참조)라고 하며 레퍼런스 카운팅으로 해결할 수 없다. 그렇다면 파이썬은 어떻게 순환 참조를 해결할까?
먼저 순환 참조는 컨테이너 객체(tuple, list, set, dict 등)에 의해서만 발생하기 때문에 모든 컨테이너 객체를 추적한다.
/*
파이썬 가비지 컬렉터가 추적하는 객체들의 예
atomic types은 추적하지 않고 containers, user-defined obejects 등을 추적한다
예외적으로 atomic type의 key와 value를 가진 dict는 추적하지 않는다
*/
>>> gc.is_tracked(0)
False
>>> gc.is_tracked("a")
False
>>> gc.is_tracked([])
True
>>> gc.is_tracked({})
False
>>> gc.is_tracked({"a": 1})
False
>>> gc.is_tracked({"a": []})
True
컨테이너 객체가 생성가 생성될 때마다 파이썬은 0세대 링크드 리스트에 추가한다.
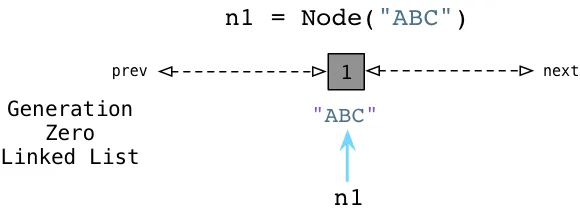
이렇게 여러 컨테이너 객체를 0세대 링크드 리스트에 추가한 뒤, 객체가 참조하는 다른 객체 확인 및 레퍼런스 카운트를 저장한다. 박스 안의 숫자는 레퍼런스 카운트이고 화살표는 참조하는 다른 객체에 의해 참조되었음을 알려준다.
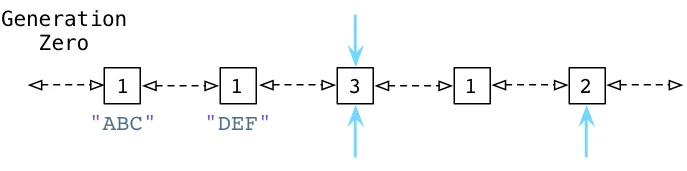
만약 순환 참조가 감지된다면 컨테이너 객체의 메모리를 해제시킨다. 그렇다면 어떻게 순환 참조를 감지할까?
파이썬의 객체에는 PyGC_HEAD 구조체가 있다
/* GC information is stored BEFORE the object structure. */
typedef union _gc_head
{
struct {
union _gc_head *gc_next;
union _gc_head *gc_prev;
Py_ssize_t gc_refs;
} gc;
long double dummy; /* force worst-case alignment */
} PyGC_Head;
구조체 안의 gc_refs 필드를 레퍼런스 카운트와 같게 설정한 후, 객체에서 참조하고 있는 다른 컨테이너 객체를 찾고, 다른 ‘컨테이너 객체’가 참조 중일 경우 에만 gc_refs 필드를 줄인다.
만약 gc_refs 필드가 0이될 경우, 컨테이너 객체에서만 참조하는 컨테이너 객체가 되기 때문에 순환 참조가 되었다 판단하고 메모리를 해제한다.

이외에 해체되지 않는 메모리들은 다음 세대로 이전되며, 마지막 2세대 까지 남아있는 객체들은 프로그램이 실행을 멈출 때까지 남아있는다.
이처럼 파이썬의 가비지 컬렉션은 확실히 죽은 객체만을 찾아 해제하는 방식을 사용한다.
가비지 컬렉션이 순환 참조를 파악하는 방식을 알아보았지만, 가비지 컬렉션이 항상 발생하는 것이 아니다.
가비지 컬렉션의 작동 방식
가비지 컬렉터는 내부적으로 generation(세대)과 threshold(임계값)로 가비지 컬렉션 주기와 객체를 관리한다. 세대는 0세대, 1세대, 2세대로 구분되는데 최근에 생성된 객체는 0세대(young)에 들어가고 오래된 객체일수록 2세대(old)에 존재한다. 더불어 한 객체는 단 하나의 세대에만 속한다.
파이썬의 기본값으로 정해진 임계값을 gc.get_threshold()로 확인해볼 수 있다
>>> gc.get_threshold()
(700, 10, 10)
위의 임계값 중에서 첫번째 값과 두 세번째 값의 동작이 다르다.
첫번째 값(0세대 임계값)의 경우 메모리에 객체가 할당된 횟수에서 해체된 횟수를 뺀 값, 즉 객체 수가 700을 초과하면 가비지 컬렉션이 실행된다는 뜻이다.
두번째 값의 경우 0세대에서 가비지 컬렉션이 실행된 횟수를 뜻한다. 0세대에서 객체수가 임계값(700)을 넘어서 가비지 컬렉션이 실행되면 남은 객체를 1세대로 이전시키고 1세대 가비지 컬렉션 횟수를 1 더한다. 또한 0세대 객체수는 0으로 초기화된다.
세번째 값은 1세대 가비지 컬렉션이 임계값(10)을 초과할 경우 가비지 컬렉션 횟수에 1이 더해진다. 이대 0세대, 1세대의 횟수를 0으로 만든다.
레퍼런스 카운팅과 달리 세대별 가비지 컬렉션의 동작은 파이썬 프로그램에서 변경할 수 있다. 가비지 컬렉터를 수동으로 조작하거나 비활성화할 수 있다.
>>> gc.set_threshold(0)
>>> gc.disable()
왜 Garbage Collection은 성능에 영향을 주나
가비지 컬렉션이 어떤 역할을 하는지를 알게 되었다. 그러면 가비지 컬렉션이 성능에 어떤 영향을 주길래 중요한 것일까? 파이썬은 GIL을 사용하기 떄문에 가비지 컬렉션을 수행하려면 응용 프로그램을 완전히 중지해야 한다. 그러므로 객체가 많을수록 모든 가비지를 수집하는 데 시간이 오래 걸린다는 것도 분명하다.
가비지 컬렉션 주기가 짧다면 응용 프로그램이 중지되는 상황이 증가하고 반대로 주기가 길어진다면 메모리 공간에 가비지가 많이 쌓일 것이다. 시행착오를 거치며 응용 프로그램의 성능을 끌어 올려야 한다.
참고하기 좋은 글로 인스타그램이 파이썬 장고 기반의 웹서버를 운영하며 다룬 가비지 컬렉터 최적화에 대한 번역 글을 추천한다.
- Instagram이 Python garbage collection을 없앤 이유 https://luavis.me/python/dismissing-python-garbage-collection-at-instagram
- Instagram이 Python garbage collection을 없앤 그 후 https://luavis.me/python/cow-friendly-python-gc
참고자료
https://medium.com/dmsfordsm/garbage-collection-in-python-777916fd3189 https://towardsdatascience.com/understanding-reference-counting-in-python-3894b71b5611 https://stackify.com/python-garbage-collection/ https://rushter.com/blog/python-memory-managment/ https://kimeuichan.github.io/posts/python-gil/ https://dgkim5360.tistory.com/entry/understanding-the-global-interpreter-lock-of-cpython https://seonghyeon.dev/python-memory-management https://www.cloudbees.com/blog/generational-gc-python-ruby