네트워크 레이어 데이터 평면
23 Jul 2021네트워크 계층
네트워크 계층은 프로토콜 스택 중 가장 복잡한 계층인 만큼, 두 평면으로 나누어서 설명한다. 이 포스트는 네트워크 계층을 데이터 평면과 제어 평면으로 나눈 데이터 평면을 설명한다.
네트워크 계층의 근본적인 역할은 송신 호스트에서 수신 호스트로 패킷을 전달하는 것이다. 송신 호스트는 인접한 라우터에게 데이터그램을 보낸다. 각 라우터의 데이터 평면 역할을 입력 링크에서 출력 링크로 데이터그램을 전달하는 것이다. 제어 평면의 역할은 데이터그램이 송신 호스트에서 목적지 호스트까지 잘 전달되게끔 로컬, 퍼 라우터 포워딩을 조정하는 것이다.
네트워크 계층의 서비스 모델이 제공할 수 있는 서비스의 종류
보장된 전달
- 이 서비스는 패킷이 소스 호스트에서부터 목적지 호스트까지 도착하는 것을 보장한다
지연 제한 이내의 보장된 전달
- 패킷의 전달 보장뿐만 아니라 호스트 간의 특정 지연 제한 안에 전달한다
순서화 패킷 전달
- 패킷이 목적지에 송신된 순서로 도착하는 것을 보장한다
최소 대역폭 보장
- 송신과 수신 호스트 사이에 특정한 비트의 전송 링크를 에뮬레이트한다. 송신 호스트가 비트들을 특정한 비트 속도 이하로 전송하는 한, 모든 패킷이 목적지 호스트까지 전달된다
보안 서비스
- 네트워크 계층은 모든 데이터그램들을 소스 호스트에서는 암호화, 목적지 호스트에서는 해독할 수 있게 하여 전송 계층의 모든 세그먼트 들에 대해 기밀성을 제공해야한다
인터넷 네트워크 계층은 최선형 서비스(best-effort service)라고 알려진 서비스를 제공한다. 최선형 서비스는 패킷을 보내는 순서대로 수신됨을 보장할 수 없을 뿐만 아니라, 목적지까지의 전송 자체도 보장될 수없다. 종단 시스템 간 지연 또한보장되지 않으며, 보장된 최소 대역폭 또한 없다. 흥미롭게도 잘 개발된 대체재가 있음에도 적절한 대역폭이 제공되는 인터넷 기반 최선형 서비스 모델이 광범위하게 사용되고 있으며, 충분히 좋다고 입증되고 있다.
What is QoS (Quality of Service)?
퍼 라우터라는 네트워크 계층의 기능은 한 라우터의 입력 링크에 도착한 데이터그램이 그 라우터의 출력 링크에 어떻게 도착하는지 결정한다. 각 라우터의 데이터 평면 역할은 입력 링크에서 출력 링크로 데이터그램을 전달하는 것이다.
패킷이 라우터의 입력 링크에 도달했을 때 그 패킷을 적절한 출력 링크로 이동시키는 것, 데이터 평면에서 구현되는 기본적인 기능이다.
포워딩(전달)
- 패킷이 라우터의 입력 링크에 도달 했을 때 라우터는 그 패킷을 적절한 출력 링크로 이동시켜야 한다.
- 운전에 비유하면 포워딩은 한 교차로를 지나는 과정
-
포워딩 테이블

IP주소 전체가 아닌 Prefix만을 적는다.
- 도착하는 패킷 헤더의 필드 값을 조사하여 패킷을 포워딩한다
- 이 값을 라우터의 포워딩 테이블의 내부 인덱스로 사용한다
라우팅 (제어 평면)
- 송신자가 수신자에게 패킷을 전송할 때 네트워크 계층은 패킷 경로를 결정해야 한다. 이러한 경로를 계산하는 알고리즘을 라우팅 알고리즘이라 한다.
- 하나의 패킷이 Source에서 Destination 까지의 경로는 다양하다.
- 다양한 경로중 최적의 경로를 선택하는 과정을 라우팅 알고리즘이라고 한다.
- 운전에 비유하면 여행 전체의 과정
이러한 라우팅 알고리즘을 통해 포워딩 테이블이 만들어 진다.

데이터 패킷은 컴퓨터에서 스위치의 통로를 지나 라우터가 정해준 경로로 이동한다.
스위치
스위치란 소규모 비즈니스 네트워크 안에서 컴퓨터, 프린터, 서버 등 모든 디바이스를 서로 연결함으로써 리소스를 쉽게 공유할 수 있도록 한다. 스위치 덕분에 이러한 연결된 디바이스들은 건물 안이건 캠퍼스 안이건 관계없이 정보를 공유하고 서로 간에 통신할 수 있다. 디바이스를 서로 연결하는 스위치 없이 소규모 비즈니스 네트워크를 구축하는 것은 불가능하다.
기기는 스위치를 통해 로컬로 연결된다
라우터
스위치가 여러 디바이스를 연결하여 네트워크를 만들듯이, 라우터는 여러 스위치 그리고 각각의 네트워크를 연결하여 더 큰 네트워크를 형성한다. 이러한 네트워크는 한 곳에 있을 수도 있고 여러 곳에 분산되어 있을 수도 있다. 궁극적으로 라우터는 트래픽을 전달하고 정보의 가장 효율적인 경로를 선택하는 디스패처 역할을 한다. 정보는 데이터 패킷을 형태로 네트워크를 거쳐 이동한다. 라우터는 회사를 세계와 연결하고, 보안 위협으로부터 정보를 보호하고, 우선순위를 가질 디바이스를 결정한다.
네트워크는 라우터를 통해 다른 네트워크에 연결된다.
패킷이 인터넷에 이르기까지의 일반적인 경로이다. 기기 > 허브 > 스위치 > 라우터 > 인터넷
스위칭과 라우팅… 참 쉽죠잉~ (1편: Ethernet 스위칭)
라우터의 내부

라우터의 내부는 소프트웨어 부분과 하드웨어 부분으로 나눠져있다. 소프트웨어 부분은 네트워크의 제어 평면 기능을 수행하고 하드웨어 부분은 데이터 평면 기능을 수행한다.
입력 포트
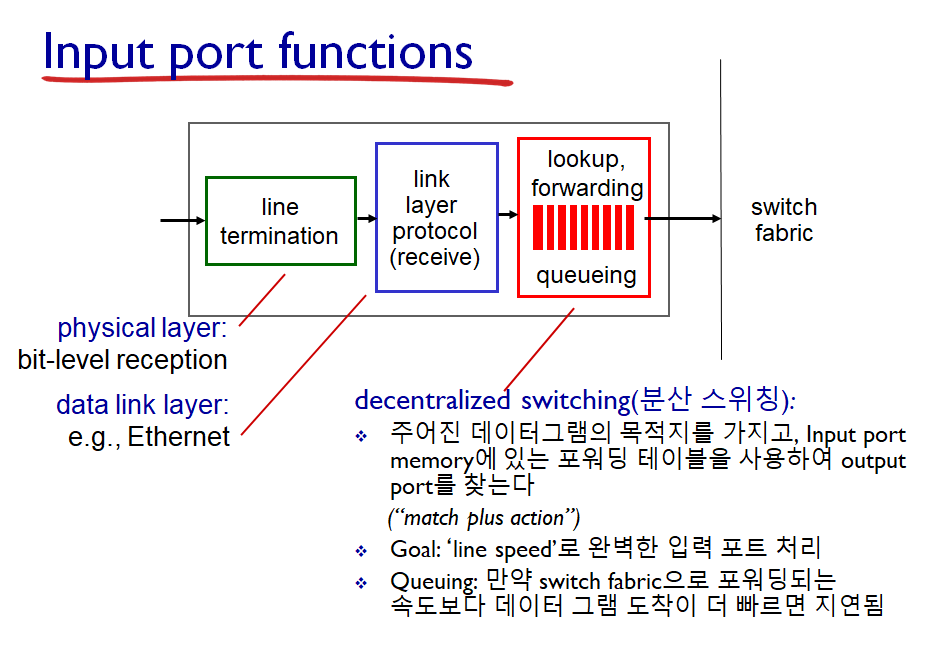
- 입력 포트의 회선 종단 기능과 링크 계층 처리는 라우터의 개별 입력 링크와 관련된 물리 계층 및 데이터 링크 계층을 구현한다.
- 입력 포트에서는 검색 기능을 수행한다. 이는 가장 오른쪽 상자에서 발생하며, 여기서 포워딩 테이블을 참조하여 도착된 패킷이 스위칭 궂를 통해 전달되는 라우터 출력 포트를 결정한다.
- 제어 패킷은 입력 포트에서 라우팅 프로세서로 전달된다.
- 큐잉 발생
출력포트
- 전송을 위한 패킷 선택 및 대기열 제거, 필요한 링크 계층 및 물리계층 전송 기능을 수행하여 출력 링크로 패킷을 전송한다.
- 큐잉 발생
스위치 구조
- 스위칭 구조는 라우터의 입력 포트와 출력 포트를 연결한다.
- 스위칭 구조를 통해 패킷이 입력포트에서 출력포트로 전달되므로 스위칭 구조는 라우터의 핵심이다. 스위칭을 하는 방법은 여러가지가 있다
- 큐잉
- 입력 큐잉
- HOL
- 회선의 앞쪽에서 다른 패킷이 막고 있을 경우, 대기 중인 패킷은 사용할 출력 포트가 사용 중이지 않아도 스위칭 구조를 통해 전송되기 위해서 기다려야 한다.
- 출력 큐잉
- AQM
- 들어오는 패킷을 저장할 메모리가 충분하지 않을 때 도착한 패킷을 폐기 한다고 알리거나 이미 대기 중인 하나 이상의 패킷을 폐기하여 공간을 확보한다.
- 버퍼가 가득 차기 전에 패킷을 폐기시켜 송신자에게 혼잡 신호를 제공하는 것이 바람직한 경우도 있다.
- 입력 큐잉
IPv4 데이터그램 형식

[RFC 791] IPv4 데이터그램의 형식. 이러한 형식이 지겹다면 레고로 표현할 수도 있다
식별자, 플래그, 단편화 오프셋은 IP 단편화와 관계가 있다. 흥미롭게도 IPv6는 단편화를 허용하지 않는다.
TTL(Time-To-Live)
- 이 필드는 네트워크에서 데이터그램이 무한히 순환하지 않도록 한다(라우팅 루프).
- 이 필드 값은 라우터가 데이터그램을 처리할 때마다 감소하고 0이 되면 폐기한다.
상위 계층 프로토콜
- 이 필드는 전송 계층의 프로토콜을 명시한다. 예를 들어 값 6은 데이터 부분을 TCP로, 값 17은 UDP로 데이터를 전달하라는 의미이다.
- [IANA Protocol Numbers 2016]에 가능한 값들이 나와있다
- 전송 계층의 포트 번호 필드와 유사한 역할이다. 네트워크 계층과 전송 계층을 묶는 역할을 한다.
헤더 체크섬
- 이 필드는 라우터가 수신한 IP 데이터 그램의 비트 오류를 탐지하는 역할을 한다.
- 헤더에서 각 2바이트(워드)를 수로 처리하고 이 1의 보수를 합산하여 계산한다.
- 헤더 체크섬의 오류 확인 방법 [참고]
IPv4 데이터그램 단편화
각각의 라우터는 다른 MTU(Maximum Transmission Unit)을 가지고, 각 IP데이터 그램은 한 라우터에서 다른 라우터로 전송하기 위해 링크 계층 프레임 내에 캡슐화되므로 링크 계층 프로토콜의 MTU는 IP 데이터그램 길이에 엄격한 제약을 둔다.
만약 두 라우터가 다른 IP 데이터 MTU를 가져서 한 쪽의 MTU가 더 작은 상황이라면 IP 데이터그램을 분할하여 각각의 더 작아진 IP 데이터그램을 별도의 링크 계층 프레임으로 캡슐화하여 출력 링크로 보낸다. 이러한 작은 데이터그램 각각을 조각(fragment) 라고 한다.
조각들은 목적지 전송 계층에 도달하기 전에 재결합되어야 한다. 실제로 TCP와 UDP 모두 네트워크 계층에서 단편화가 되지 않은 완벽한 세그먼트를 수신하는 것을 기대한다. IPv4 설계자는 네트워크 라우터가 아닌 종단 시스템에서 데이터그램 재결합을 하도록 결정했다.
목적지 호스트가 같은 출발지로부터 일련의 데이터그램을 수신하면 이러한 데이터그램이 원본 데이터그램 조각인지 판단해야 한다. 데이터 그램이 조각이라 판단되면 마지막 조각을 수신할 때 원본 데이터 그램을 만들기 위해 조각을 결합하는 방법을 결정해야 한다. 이러한 재결합의 과정을 위해 식별자, 플래그, 단편화 오프셋 필드를 헤더에 담았다.
IP 주소를 할당하는 방법으로 과거에는 네트워크 부분을 8, 16, 24비트로 제한하여 서브넷 주소를 갖는 서브넷을 각각 A, B, C 클래스 네트워크로 분류했기 때문에 이러한 주소체계를 클래스 주소체계라고 한다.
그러나 이러한 분류법은 10000개의 IP가 필요할 경우 바이트로 구분한 B클래스를 사용하여 16비트를 할당 받을 경우 65535 개의 IP를 사용하지만 실질적으로 10000개 밖에 사용하지 않아 50000개의 잉여 IP가 발생하기 때문에 비효율적이다.
전 세계 인터넷에서 모든 호스트와 라우터의 각 인터페이스는 고유한 IP 주소를 갖는다. 이러한 주소는 마음대로 선택할 수 없다. 인터페이스의 IP 주소 일부는 연결된 “서브넷“이 결정할 것이다.
“서브넷 마스크”는 IP 주소와 마찬가지로 32비트 수지만 용도는 호스트 주소 지정이 아니고 네트워크, 서브넷 비트 및 호스트 비트에 해당하는 네트워크 주소 부분을 송수신하는 데 있다. 서브넷 마스크는 모든 호스트 비트를 0으로 설정하고 모든 네트워크, 서브넷 비트를 1로 설정하는 방법으로 구축한다.
인터넷 주소 할당 방식
CIDR(Classless Interdomain Routing)[RFC 4632]는 서브넷 주소체계 표기를 일반화하고 있다.
32비트 IP주소를 두 부분으로 나누고, 이것은 다시 점으로 된 십진수 형태의 a.b.c.d/x를 가지며, 여기서 x는 주소 첫 부분의 비트 수이다.
a.b.c.d./x/ 형식 주소에서 최상위 비트(MSB)를 의미하는 x는 IP주소의 네트워크 부분을 구성한다. 이를 해당 주소의 프리픽스(prefix)라고 부른다. 한 기관은 통산 연속족인 주소의 블록을 할당 받는다. 이 경우에 기관 장비들의 IP 주소는 공통 프리픽스를 공유한다.
주소의 나머지 32 - x 비트들은 기관 내부에 같은 네트워크 프리픽스를 갖는 모든 장비들을 구별하기 위해 사용된다. 이 하위 비트들은 추가 서브넷 구조를 가질수도 있다. 예를 들어, CIDR식 주소 a.b.c.d/21의 첫 21비트들은 기관의 네트워크 프리픽스를 나타내고 이 기관의 모든 장비의 IP 주소에 공통부분이라고 가정할 때, 나머지 11비트들은 기관 내부의 특정 호스트들을 식별한다. 예를 들면 a.b.c.d/24는 기관 내부의 특정 서브넷을 나타낼 수 있다.
CIDR은 서브넷팅은 개념상 동일하다. CIDR은 ISP 수준 이상일 때 사용되고, 기관 및 조직에서는 서브넷을 사용한다.
주소 블럭 획득
기관의 서브넷에서 사용하기 위한 IP 주소 블록을 얻기 위해, 네트워크 관리자는 먼저 이미 할당받은 주소의 큰 블록에서 주소를 제공하는 ISP와 접촉해야 한다.

각 조직에서 앞의 파란 글씨가 prefix 부분이고 뒤에 빨간 글씨가 8개의 작은 주소 블록으로 나눈다
ISP가 할당 받은 주소 200.23.16.0/20을 작은 주소 블록 8개로 나눈다.
ISP로부터 주소를 획득하는 방법 이외에는 ICANN [RFC7020]의 지역 인터넷 등록에서 지역 내 주소의 할당 및 관리를 제어할 수 있다.
호스트 주소 획득: 동적 호스트 구성 프로토콜(DHCP)
Dynamic Host Configuration Protocol
기관이 ISP로부터 주소 블록을 획득하여, 개별 IP 주소를 기관 내부의 호스트와 라우터 인터페이스에 할당한다. 시스템 관리자는 라우터 안에 IP 주소를 할당한다. 호스트에 IP 주소를 할당하는 것은 수동으로 구성이 가능하지만 일반적으로 동적 호스트 구성 프로토콜(DHCP)을 더 많이 사용한다.
DHCP는 호스트 IP 주소의 할당뿐만 아니라, 서브넷 마스크, 첫 번째 홉 라우터(디폴트 게이트웨이)주소나 로컬 DNS 서버 주소 같은 추가 정보를 얻게 해준다.
DHCP는 호스트가 빈번하게 접속하고 떠나는 가정 인터넷 접속 네트워크, 무선 LAN에서도 폭넓게 사용한다. 기숙사에서 도소관, 강의실, 카페로 이동ㅎ는 학생은 각 지역에서 새로운 서브넷에 접속할 것이며, 각 지역마다 새로운 IP 주소가 필요할 것이다. 이러한 경우 DHCP는 아주 적합하다.
DHCP는 클라이언트/서버 프로토콜이다. 새로운 호스트가 도착할 경우, DHCP 프로토콜은 4단계
의 과정을 통하여 새로운 주소를 할당한다.

DHCP 패킷의 구조. https://jinheeahn.wordpress.com/2015/10/28/4-dhcp-packet-설명-1/
- DHCP 서버 발견
- DHCP 클라이언트는 링크 계층으로 IP 데이터 그램을 보내며 이 프레임은 서브넷에 연결된 모든 노드로 브로드캐스팅 된다.
- DHCP 서버 제공
- DHCP 발견 메시지를 받은 서버는 DHCP 제공 메세지를 클라이언트로 응답한다. 이 때에도 브로드캐스트 주소를 사용하여 서브넷의 모든 노드로 이 메시지를 브로드캐스트한다.
- DHCP 요청
- 새롭게 도착한 클라이언트는 하나 또는 그 이상의 서버 제공자 중에서 선택할 것이고 선택된 제공자에게 파라미터 설정으로 되돌아오는 DHCP 요청 메시지로 응답한다.
- DHCP ACK
- 서버는 DHCP 요청 메세지에 대해 요청된 파라미터를 확인하는 DHCP ACK 메시지로 응답한다

Discover, Offer, Request, ACK를 합쳐 DORA라고 표현한다.
DHCP는 ACK 메세지를 받으면, 상호 동작은 종료되고 클라이언트는 IP주소를 임대 기간 동안 사용할 수 있다.
네트워크 주소 변환(Network Address Translation)
최근에 SOHO(Small office, Home office)네트워크 확산으로 인해서 SOHO가 장치를 연결하기 위해 LAN을 설치할 때마다 ISP는 모든 SOHO의 IP 장치를 수용할 수 있는 주소 범위를 할당해야 한다. 네트워크가 현저하게 커지면 큰 주소 블록이 할당되어야 한다. 하지만 ISP가 이미 SOHO네트워크의 해당 주소 범위에 인접한 부분을 할당해버렸다면? 또 특정 홈네트워크 소유자가 IP 주소가 어떻게 관리되는지 알고자 한다면? 이런 상황에서는 네트워크 주소 변환(NAT)[RFC 2663]으로 주소를 할당할 수 있다.
NAT가능 라우터는 홈 네트워크의 일부인 인터페이스를 갖는다. 홈 네트워크의 인터페이스는 모두 같은 네트워크 주소를 갖는다. 사설망 또는 사설 개인 주소를 갖는 권역(realm)을 위해 사설망[RFC 1918]에 예약된 IP 주소 공간 세 부분 중의 하나이다(사설망). 이러한 사설 주소(홈 네트워크)는 글로벌 네트워크와는 분리되어 패킷 전달이 불가능하다. 왜냐하면 이 주소들(사설망)의 블록은 주어진 홈 네트워크 내부에서만 의미가 있기 때문이다. 그러나 사설 주소가 주어진 네트워크에서만 의미가 있다면, 패킷의 유일한 주소가 필요한 글로벌 인터넷과의 송수신에는 어떻게 처리할 수 있을까?
NAT 가능한 라우터는 외부 세계로는 라우터처럼 보이지 않는다. 대신 NAT 라우터는 외부세계로는 하나의 IP 주소를 갖는 하나의 장비로 동작한다. (이 IP주소는 DHCP 서버로부터 주소를 얻는다.)

NAT 가능한 라우터를 사용하는 홈 네트워크가 글로벌 네트워크를 사용하기 위한 과정. 192.168.X.Y 또한 사설망에 포함된다
홈 라우터를 떠나 글로벌 네트워크(인터넷)으로 가는 트래픽은 출발지 IP주소를 가지며 홈으로 들어오는 트래픽은 목적지 IP주소를 가진다. 본질적으로 NAT 가능 라우터는 외부에서 들어오는 홈 네트워크의 상세한 사항을 숨긴다.
WAN에서 같은 목적지 IP 주소를 갖는 NAT 라우터에 모든 데이터 그램이 도착하면, 트래픽이 라우터가 주어진 데이터그램을 전달하는 내부 호스트를 알 수 있는 방법은 무엇인가? NAT 변환 테이블을 사용하여 그 테이블에 IP주소와 포트 번호를 포함시킨다.

NAT 가능한 라우터는 사설망(Private Interface)과 공용망(Public Interface) 둘 다 가지고 있다.
The Network Address Translation Table
NAT의 단점
- 변화를 수행하여 경로가 지연된다
- NAP를 사용하는 동안에는 특정 애플리케이션이 작동하지 않는다
- IPsec와 같은 터널링 프로토콜을 복잡하게 만든다
- 네트워크 계층에서 전송 계층의 포트번호를 변조하게 된다
IPv6
 IPv4에 비해 IPv6는 40바이트의 간소화된 헤더를 가지고 있다.
IPv4에 비해 IPv6는 40바이트의 간소화된 헤더를 가지고 있다.
버전
- IPv4와 IPv6를 필드 값 ‘4’, ‘6’으로 구분한다.
트래픽 클래스
- IPv4의 Type Of Service와 비슷한 의미로 만든 8비트 필드로, 흐름 내의 SMTP 이메일 같은 애플리케이션의 데이터그램보다 voice-over-IP 같은 특정 응용 데이터그램에 우선순위를 부여한다.
흐름 라벨(Flow Label)[RFC 2460]
- “비 디폴트 품질 서비스나 실시간 서비스와 같은 특별한 처리를 요청하는 송신자에 대해 특정 흐름에 속하는 패킷 레이블링을 가능하게 한다.”
- 오디오/비디오 전송은 흐름에 속하고 파일, 전자메일은 흐름에 속하지 않는다.
- 20비트 필드이다.
페이로드 길이
- 이 16비트 값의 필드는 IPv6 데이터그램에서 고정 길이 40바이트 패킷 헤더 뒤에 나오는 바이트 길이이며 부호 없는 정수이다.
다음 헤더
- 이 필드는 데이터그램의 내용이 전달될 프로토콜을 구분한다(TCP, UDP) 이 필드는 IPv4의 헤더에 있는 Protocol 필드와 같다.
홉 제한
- 이 필드의 내용은 라우터가 데이터그램을 전달할 때마다 1씩 감소한다. 홉 제한 수가 0보다 작아지면 데이터그램을 버린다.
데이터
- 데이터그램이 목적지에 도착하면 IP 데이터그램에서 페이로드를 제거한 후, 다음 헤더 필드에 명시한 프로토콜에 전달한다.
IPv4와 비교해서 없어진 것
단편화,재결합 : IPv6에서는 라우터가 받은 IPv6 데이터그램이 너무 커서 출력 링크로 전달할 수 없다면 라우터는 데이터그램을 폐기하고 “패킷이 너무 크다(Packet Too Big)”라는 ICMP 오류메시지를 송신자에게 보낸다.
단편화와 재결합은 시간이 걸리므로 라우터에서 이 기능을 삭제하고 종단 시스템이 하도록 하는 것이 네트워크에서 IP 전달 속도를 증가시킨다
헤드 체크섬 : 트랜스포트 계층과(TCP,UDP) 데이터 링크 프로토콜에서(이더넷) 체크섬을 수행하므로 IP 설계자는 네트워크 계층의 체크섬 기능이 반복되는 것으로 생략해도 될 것이라 생각했다.
옵션 : 옵션 필드는 더 이상 표준 IP 헤더 필드가 아니다. 옵션 필드가 제거되었기에 표준에서는 고정길이 40바이트의 IP 헤더를 갖게 되었다.
IPv6 전환법
IPv4를 IPv6로 전환하는 방법중 실제로 널리 사용하는 방법은 터널링[RFC 4213]이다.
두 IPv6 노드가 IPv6 데이터그램을 사용해서 작동한다고 가정해보자. 물론 이들은 IPv4 라우터를 통해 연결되어 있다. 두 개의 IPv6 노드 사이에 있는 IPv4 라우터들을 터널이라고 한다.

IPv6 network에서 라우터로 전송될 때 캡슐화가 진행된다.
터널의 송신 측에 있는 IPv6 노드는 IPv6 데이터그램을 받고 IPv4 데이터그램의 데이터 필드에(페이로드) 이것을 넣는다. 이 IPv4 데이터그램에 목적지 주소를 터널의 수신 측에 IPv6 노드로 적어서 터널의 첫 번째 노드에 보낸다. 터널 내부에 있는 IPv4 라우터는 IPv4 데이터그램이 IPv6 데이터그램을 가지고 있다는 사실을 모른 채 다른 데이터그램을 처리하는 방식으로 IPv4 데이터그램을 처리한다. 터널 수신 측에 있는 IPv6 노드는 IPv4 데이터그램을 받고 (데이터그램 프로토콜 번호 필드가 41일 경우 IPv4의 페이로드는 IPv6 의 데이터그램임을 나타낸다) IPv6 데이터그램으로 만든 다음에 IPv6 노드에 보낸다.